В настоящей главе мы объясним вам, как Форт-система управляет вводом-выводом, как текст поступает с клавиатуры и выводится на экран дисплея, как данные записываются во внешнюю память и считываются из нее. Особое внимание будет уделено командам доступа к дискам, вывода, работы со строками, ввода и преобразования вводимых чисел.
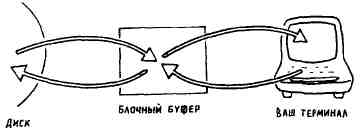
Форт-система построена таким образом, чтобы вы не задумывались о том, как организованы блочные буферы. Однако ничего сложного в этом нет, так что вы всегда сможете в них разобраться, применить и (при необходимости) исправить их. Поэтому мы опишем здесь механизм работы блочных буферов.
Как уже упоминалось ранее, каждый буфер имеет достаточные размеры для размещения содержимого одного блока (1024 байта) в памяти с произвольной выборкой (ОЗУ), поэтому он может редактироваться и загружаться или к нему просто может быть осуществлен доступ любыми иными средствами. Мы думаем, что непосредственно взаимодействуем с диском, хотя на самом деле система перекачивает данные с диска в буфер, откуда их можно считывать. Можно также записать данные в буфер с тем, чтобы система переслала их дальше, на диск.
Здесь мы имеем дело с так называемой виртуальной памятью, т.е. работаем с памятью большой емкости, как с памятью компьютера.
Во многих Форт-системах (даже если они являются мультипрограммными) используются всего лишь два блочных буфера. Давайте выясним, почему это возможно.
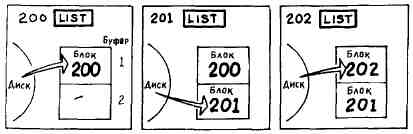
Допустим, в вашей системе имеются два буфера и вы выполняете следующие действия. Сначала вы распечатываете блок 200. Система считывает его с диска и пересылает в буфер 0, откуда слово LIST выводит этот блок на печать. Далее вы распечатываете блок 201. Система копирует блок 201 с диска в другой буфер. И наконец, вы распечатываете блок 202. Система копирует данный блок с диска в буфер, который применялся в первую очередь, а именно в буфер 0.
Что случилось с бывшим содержимым буфера 0? Оно просто было замещено (затерто) новым содержимым. Старая информация для нас не потеряна, так как блок 200 все еще остается на диске. Но если бы вы отредактировали блок 200, были бы утеряны ваши исправления? Нет, конечно. При распечатке блока 202 сначала измененное содержимое блока 200 посылается на диск с тем, чтобы обновить прежнее содержимое этого блока, а затем в буфер помещается содержимое блока 202.
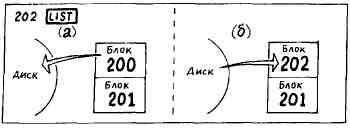
Волшебное слово UPDATE устанавливает (обновляет) флаг, связанный с каждым буфером. Этот флаг указывает, что содержимое текущего блока (к которому осуществлялся самый последний доступ) после прочтения с диска подвергалось изменениям. Все команды редактора, изменяющие содержимое блоков, - будь то занесение или удаление - имеют слово UPDATE в своих определениях. Если в некоторый буфер требуется поместить содержимое другого блока и флаг обновления данного буфера установлен, прежнее содержимое не исчезает, а копируется снова на диск.
Основным словом, которое считывает содержимое какого-либо блока с диска, является BLOCK. Например, если вы введете
205 BLOCK
то система скопирует блок 205 в один из буферов. Кроме того, BLOCK оставляет в вершине стека адрес начала этого буфера. Используя адрес начала буфера как базу, вы можете получить доступ к любому байту блока1. Слово BLOCK получает управление всякий раз, когда вы распечатываете содержимое блока посредством LIST или загружаете его с помощью LOAD.
Рассмотрим выполнение слова BLOCK более подробно. В первую очередь BLOCK проверяет, не находится ли уже содержимое нужного блока в некотором буфере, и если оно там находится, то помещает в вершину стека адрес данного буфера, а если нет - выбирает буфер (в большинстве систем буфер с самым давним доступом). В том случае, когда буфер подвергался изменениям, система копирует его содержимое на диск, а затем копирует содержимое нужного блока в этот буфер.
Такая организация позволяет многократно модифицировать содержимое блока, не обращаясь всякий раз к дисководу. Поскольку обращение к диску занимает больше времени, чем к памяти с произвольной выборкой, при этом экономится масса времени.
С другой стороны, когда в одной системе работают несколько пользователей, подобная организация дает им возможность обходиться всего лишь двумя буферами (2К памяти) даже в том случае, если каждый из них осуществляет доступ к различным блокам.
Многие Форт-системы предоставляют своим пользователям право задавать число блочных буферов, обеспечивая им тем самым возможность выбора между размером доступной оперативной памяти и частотой обращения к дискам.
Слово FLUSH (ВЫБРОС) инициирует немедленную запись всех обновленных буферов на диск. (Так как вы теперь имеете представление о буферах, можно объяснить, для чего нужно слово FLUSH: обновление буфера не означает записи его содержимого на диск.) Помимо прочего после употребления слова FLUSH система «забывает», что в буферах хранилось содержимое блоков (она освобождает все буферы). Если вам понадобится распечатать или загрузить один из таких блоков, то придется считать его содержимое посредством BLOCK с диска снова.
1 Для пользователей некоторых систем фиг-Форта. Блоки, занимающие 1024 байта, могут быть считаны в нескольких несмежных буферов, что затрудняет индексирование блоков (см. листинги системы фиг-Форта).
Определенное Стандартом-83 слово SAVE-BUFFERS (СОХРАНИТЬ-БУФЕРЫ) по своим возможностям беднее слова FLUSH: оно сохраняет на диске содержимое обновленных буферов, но не освобождает их. Если вам снова потребовался некоторый блок, то его содержимое уже находится в одном из буферов, и Форт-система в этом случае не обращается к диску.
Как правило, вам нет необходимости пользоваться приведенными выше словами, поскольку слово BLOCK гарантирует, что перед повторным применением буферов их содержимое будет сохранено на диске. Однако во время отладки новой программы вам эти слова могут пригодиться (прежде чем система выйдет из строя, исправления все же должны попасть на диск). SAVE-BUFFERS переписывает хранящиеся в буферах блоки на диск, но с содержимым буферов можно работать и в дальнейшем. Это сокращает число обращений к диску (что экономит время и позволяет избежать многих неприятностей). Слово FLUSH необходимо при смене дисков, так как оно эффективно освобождает буферы от их прежнего содержимого, или в тех случаях, когда вы хотите убедиться в том, что информация действительно была записана на диск.
К сожалению, перечисленные слова и их функции изменяются от диалекта к диалекту до неузнаваемости. Ниже приводятся описания этих слов для различных систем.
| Фиг-Форт | FLUSH
Копирование всех обновленных буферов во внешнюю память и их освобождение | SAVE-BUFFERS
(Не определено) |
| Стандарт-79 | (Не определено: переименованное слово SAVE-BUFFERS) | Копирование всех обновленных буферов во внешнюю память и их освобождение |
| Стандарт-83 | Копирование всех обновленных буферов и их освобождение | Копирование всех обновленных буферов во внешнюю память, сброс флагов обновления этих буферов без их освобождения |
На всех диалектах слово EMPTY-BUFFERS заставляет систему «забыть» о том, что у нее какие-то блоки размещены в буферах и сбрасывает все флаги обновления без записи содержимого блоков на диск. EMPTY-BUFFERS полезно применять в тех случаях, если вы случайно испортили1 содержимое некоторого буфера (на-
1 Для начинающих. Испорченные, бессмысленные или не имеющие отношения к обработке, ради которой были введены, данные программисты называют «мусором».
пример, удалили несколько нужных строк, а их текст забыт или просто что-нибудь напутали) и не хотите, чтобы оно попало на диск. Когда вы после выполнения этого слова снова читаете свой блок, система не выясняет, есть ли содержимое вашего блока в памяти, а просто считывает его с диска1.
Согласно Стандарту-83 слово FLUSH можно определить следующим образом:
: FLUSH SAVE-BUFFERS EMPTY-BUFFERS ;
Слово BUFFER заносит информацию на диск без учета прежнего содержимого диска (например, при инициализации диска, записи потока информации, копировании ленты на диск и т. д.).
BUFFER используется словом BLOCK для назначения номера блока следующему доступному буферу. Само слово
BUFFER содержимое с диска в буфер не считывает (хотя в некоторых системах считывает). К тому же оно не проверяет, был ли номер блока присвоен какому-либо буферу, и может случиться так, что один и тот же номер будут иметь два буфера. Такую ситуацию вы обязаны контролировать сами.
UPDATE |
( -- ) |
Блок, доступ к которому осуществлялся в последнюю очередь, отмечается как модифицируемый. Этот блок будет впоследствии переписан во внешнюю память, если его буфер потребуется для размещения другого блока или в результате выполнения слова FLUSH. |
SAVE-BUFFERS |
( -- ) |
Запись содержимого всех обновленных буферов в соответствующие блоки внешней памяти. У всех буферов погашается признак обновления, но они продолжают оставаться распределенными . |
FLUSH |
( -- ) |
Осуществляется SAVE-BUFFERS, затем происходит погашение признака обновления всех буферов. Используется при установке или смене накопителей внешней памяти. |
EMPTY-BUFFERS |
( -- ) |
Все блочные буфера отмечаются как пустые независимо от им содержания. Обновленные блоки во внешнюю память не записываются. |
BLOCK |
( u -- ) |
Занесение в стек адреса первого байта в блоке u. Если данного блока еще в памяти нет, то происходит его пересылка из внешней памяти в тот буфер, к которому дольше всех не было доступа. Если блок, занимающий данный буфер, обновлялся (то есть был модифицирован) , то перед считыванием блока u в буфер содержимое последнего будет переписано во внешнюю память. |
BUFFER |
( u -- a) |
Функции те же, что и у BLOCK, за исключением того, что сам блок из внешней памяти не считывается. |
1 для пользователей мультипрограммной системы. Будьте осторожны! Слово
EMPTY-BUFFERS освобождает все буферы. Программа для работы с базой данных, широко применяющая средства восстановления после ошибок, не должна делать это с помощью
EMPTY-BUFFERS. Но Форт-программы, использующие блоки, легко расширить с тем, чтобы они удовлетворяли запросы любой пользовательской программы.
Слово EMIT берет из стека одно значение в коде ASCII, используя только младший байт, и выводит этот символ. Например, при текущей десятичной системе счисления вы получите такой результат:
65 EMIT A ok 66 EMIT B ok
Слово TYPE выводит всю строку символов при ее заданном начальном адресе и счетчике в следующей форме:
( a количество -- )
Вам уже встречалось слово TYPE в определениях, связанных с форматированием чисел, но тогда не нужно было заботиться ни об адресе, ни о счетчике, так как их значения обеспечивались словом #> автоматически.
Зададим слову TYPE адрес, по которому, как нам известно, находится строка символов. Напомним, что начальный адрес буфера входного текста задается словом TIB (см. гл. 9 о вариантах диалектов). Допустим, вы вводите команду:
TIB 11 TYPE
В результате будет выведено 11 символов из буфера входного текста, который содержит только что введенную команду:
TIB 11 TYPE<return>TIB 11 TYPEok
TYPE |
( а количество - ) |
Происходит выдача заданного количества символов, начиная с заданного адреса, на текущее внешнее устройство |
Ранее уже отмечалось, что слово BLOCK копирует заданный блок в некоторый доступный буфер и оставляет адрес последнего в вершине стека. Приняв этот адрес за исходный, мы можем добраться посредством индексирования до каждого из 1024 байтов данного буфера и вывести любую строку. К примеру, для того чтобы вывести строку 0 блока 214, вы можете ввести
CR 214 BLOCK 64 TYPE<return> ( ЭТО БЛОК 214 ) ok
Для вывода строки 8 нужно добавить к исходному адресу 512 (8x64):
CR 214 BLOCK 512 + 64 TYPE
Прежде чем перейти к более интересному примеру, нам бы хотелось предложить вашему вниманию еще два слова, которые ассоциируются со словом TYPE.
-TRAILING |
( a u1 -- a u2) |
Удаление незначащих пробелов из строки с заданным адресом путем уменьшения значения счетчика от u1 (счетчик исходных байтов) до u2 (счетчик байтов, полученных в результате вычеркивания пробелов). |
>TYPE |
( a # -- ) |
То же самое, что и TYPE, за исключением того, что перед выдачей выводимая строка помещается в pad. Используется в мультипрограммных системах для вывода строк, находящихся в блоках на диске. |
Слово -TRAILING, используемое непосредственно перед командой TYPE, изменяет значение счетчика таким образом, что незначащие пробелы не выводятся. Так, если вы вставите это слово в приведенный выше пример (с блоком 214), то получите:
CR 214 BLOCK 64 -TRAILING TYPE<return> ( ЭТО БЛОК 214 ) ок
Это слово удаляет незначащие пробелы в конце (32 в коде ASCII), но не препятствует другим не выводимым на печать символам (например, 0 в коде ASCII).
Слово >TYPE применяется только в мультипрограммных системах для вывода строк из буферов, находящихся на диске. Вместо того чтобы непосредственно выдавать строку с заданного адреса, оно предварительно перекачивает строку целиком в рабочую область и затем выводит ее оттуда. Поскольку все пользователи разделяют одни и те же буферы, система не может гарантировать, что к тому времени, когда TYPE завершит вывод содержимого какого-то буфера, последний будет все еще хранить прежний блок. Однако вы можете быть уверены в том, что данный буфер содержит один и тот же блок во время перекачки этого буфера в рабочую область1. Так как каждой задаче отведена своя рабочая область, >TYPE может выводить из нее информацию без риска получить не те данные.
В приведенном ниже примере используется слово TYPE, но вы при необходимости можете подставить вместо него >TYPE. В конце раздела мы покажем вам полезный прием с применением генератора случайных чисел.
Block # 231 0 ( Генератор бессмысленных сообщений ) 1 : АБРЕД ( -- а) 232 BLOCK ; 2 : БРЕД ( строка# столбец# -- а) 3 20 * SWAP 64 * + АБРЕД + ; 4 : .БРЕД ( столбец# колонка# -- ) БРЕД 2И -TRAILING TYPE ; 5 : 1ПРИЛАГАТЕЛЬНОЕ 10 CHOOSE 0 .БРЕД ; 6 : 2ПРИЛАГАТЕЛЬНОЕ 10 CHOOSE 1 .БРЕД ; 7 : СУЩЕСТВИТЕЛЬНОЕ 10 CHOOSE 2 .БРЕД ; 8 : ФРАЗА 1ПРИЛАГАТЕЛЬНОЕ SPACE 2ПРИЛАГАТЕЛЬНОЕ SPACE СУЩЕСТВИТЕЛЬНОЕ ; 9 : СООБЩЕНИЕ 10 CR ." Применяя " ФРАЗА ." имея в виду " 11 CR ФРАЗА ." представляется возможным даже несмотря на " 12 CR ФРАЗА . " функционировать как " 13 CR ФРАЗА ." при существующих ограничениях на " 14 CR ФРАЗА ." . " ; 15 СООБЩЕНИЕ
Block # 232 0 высокий культурный уровень 1 общий производственный интерес 2 автоматизированный наукоемкий комплекс 3 запланированный валовой объем 4 интегрированный цифровой коэффициент 5 квалифицированный многоотраслевой принцип 6 представительный химический генератор 7 автономный аппаратный интерфейс 8 цифровой независимый автомат 9 синхронизированный функциональный критерий 10 систематизированный коротковолновой проект 11 12 13 14 15
1 Для специалистов. В мультипрограммной системе задача передает управление центрального процессора следующей задаче только на время ввода-вывода или по специальной команде, которая преднамеренно не включена в определение слова, пересылающего строки.
После загрузки блока (в нашем примере блока 231) вы получите следующий текст, хотя некоторые слова при выполнении слова СООБЩЕНИЕ всякий раз будут меняться:
применяя высокий функциональный критерий имея в виду цифровой производственный комплекс представляется возможным даже несмотря на представительный независимый коэффициент функционировать как автоматизированный наукоемкий уровень при существующих ограничениях на квалифицированный Функциональный автомат.
Как видите, определение слова СООБЩЕНИЕ состоит из ряда сочетаний ." текст", перемежаемых словом ФРАЗА. Если вы выполните слово ФРАЗА отдельно, то получите
ФРАЗА автоматизированный культурный объем ok
т. е. одно слово выбирается случайным образом из столбца 0 блока 232, другое - из столбца 1, а третье - из столбца 2.
Вы, конечно, заметили, что в определении слова ФРАЗА есть обращения к трем словам верхнего уровня: 1 ПРИЛАГАТЕЛЬНОЕ, 2ПРИЛАГАТЕЛБНОЕ и СУЩЕСТВИТЕЛЬНОЕ. Каждое из перечисленных слов в свою очередь обращается к слову .БРЕД, которому в качестве аргументов необходимо взять из стека номер строки (0-9) и номер столбца (0-2), определяющие выводимое слово или фразу. Случайное число, получаемое при выполнении выражения "10 CHOOSE", определяет номер строки. Каждая часть речи обеспечивает уникальный номер столбца.
Слово .БРЕД обращается к слову БРЕД для вычисления адреса бессмысленного сообщения, передавая максимальное значение счетчика, равное 20, слову TYPE. Но прежде слово -TRAILING сокращает значение 20 до фактического числа значащих символов в строке, удаляя тем самым незначащие пробелы в конце. Слово БРЕД вычисляет величину смещения в блоке путем умножения номера столбца на 20 (каждый столбец занимает 20 символов) и номера строки на 64 (каждая строка состоит из 64 символов), после чего складывает полученное смещение с. адресом начала, которое доставляется словом АБРЕД. Вообще хороший стиль программирования предполагает разделение программ, вычисляющих адреса, и программ, эти адреса использующие (так как адреса зачастую оказываются необходимыми для других целей).
Адрес начала обеспечивает слово АБРЕД, которое просто вызывает BLOCK. Здесь мы снова выделили получение адреса в отдельное действие на тот случай, если местоположение базы данных с бессмысленными выражениями изменится. Например, может измениться номер блока. Такое разбиение не мешает нам даже поместить базу данных в словарь (путем переопределения слова АБРЕД).
CREATE АБРЕД 64 10 * ALLOT
Полезный прием. Генератор случайных чисел. Этот простой генератор случайных чисел может быть использован в играх. Для более же серьезных применений, например моделирования, существуют улучшенные варианты такого генератора.
( Генератор случайных чисел - верхний уровень )
VARIABLE RND HERE RND ! : RANDOM ( -- ) RND в 31421 * 6927 + DUP RND ! ; : CHOOSE ( u1 -- u2 ) RANDOM UM* SWAP DROP ; ( где CHOOSE оставляет на стеке случайное число в диапазоне от 0 до u1-1 )
Для получения некоторого случайного числа в диапазоне от 0 до 10 (само число 10 сюда не входит) просто наберите на клавиатуре
10 CHOOSE
и в вершине стека останется случайное число.
Команды для пересылки строк литер или массивов данных весьма просты. Каждой команде требуются три аргумента: исходный адрес, конечный адрес и значение счетчика.
MOVE |
( a1 a2 u -- ) |
По ячеечное копирование участка памяти длиной u байтов, начинающегося с адреса a1, в участок памяти, начинающийся с а2. Пересылка идет с al В сторону увеличения адресов. |
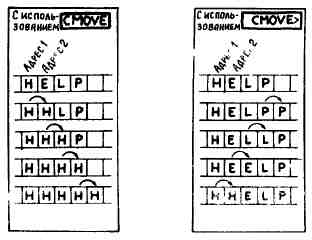
CMOVE |
( al a2 u -- ) |
Побайтное копирование участка памяти длиной u байтов, начинающегося с a1, в участок памяти, начинающийся с а2. Пересылка идет с а1 в сторону увеличения адресов. |
СМОVE> |
( a1 a2 u -- ) |
Копирование участка памяти длиной u байтов, начинающегося с адреса a1, в участок памяти, начинающийся с адреса а2. Копирование начинается с КОНЦА строки и продвигается в сторону уменьшения адресов. |
Заметим, что для этих команд существуют определенные соглашения (рассмотренные ранее):
Поэтому для перечисленных трех слов аргументы следуют в таком порядке: (источник адресат счетчик --). Для того чтобы переслать содержимое всего буфера в рабочую область, вы могли бы, к примеру, написать:
210 BLOCK PAD 1024 CMOVE
хотя на машинах с поячеечной адресацией памяти намного быстрее выполнялась бы последовательная пересылка ячеек (ячейка за ячейкой):
210 BLOCK PAD 1024 MOVE
Слово CMOVE> позволяет пересылать некоторую строку в область, которая расположена в памяти с большими адресами, но пересекается с исходной областью1.
Для заполнения некоторого массива пробелами вы можете воспользоваться уже знакомым вам словом BLANK2. Например, внесите пробелы в 1024 байта рабочей области:
PAD 1024 BLANK
Это равносильно выражению:
PAD 1024 BL FILL
В большинстве систем слово BL определено как константа со значением 32.
1 для начинающих Предположим, вы хотите передвинуть некоторую строку в памяти на один байт вправо (например, когда текстовый редактор включает в текст некоторый символ) Применив команду
CMOVE, вы скопировали бы первую букву строки во второй байт, но при этом вторая литера строки оказалась бы «испорченной» В результате получилась бы строка, составленная из одного и того же символа Чтобы сохранить исходную строку, в данной ситуации нужно воспользовался словом
CMOVE>
2 для пользователей систем фиг-Форта. В вашей системе это слово BLANKS (ПРОБЕЛЫ)
BLANK |
( a u -- ) |
Заполнение участка памяти длиной u байт символам пробела в коде ASCII. |
Остроумный, но не согласующийся со стандартом прием: для заполнения участка памяти многобайтным шаблоном примените слово CMOVE. При выполнении следующего выражения 20-байт-ный массив будет заполнен 10-ю копиями 16-разрядного адреса слова НОП:
CREATE ТАБЛИЦА ' НОП , 18 ALLOT \ 10 ячеек
ТАБЛИЦА DUP 2+ 18 CMOVE \ инициализация выделенной памяти
\ адресом МОП
Слово KEY (КЛАВИША) ожидает, пока вы нажмете какую-либо клавишу на панели терминала и оставляет в вершине стека в младшем по порядку байте эквивалент символа, соответствующего этой клавише, в коде ASCII.
Наберите на клавиатуре:
KEY<return>
Курсор продвинется на одну позицию, но «ok» на терминале не высветится: система ждет ввода вашего символа. Нажмите, к примеру, клавишу А и Форт-система ответит вам: «ok». Теперь в вершине стека находится значение литеры А в коде ASCII, поэтому введите
.<return> 65 ok
Это дает вам возможность определить значение символа в коде ASCII, не заглядывая в таблицу.
Вы можете также включить KEY в состав определения. При встрече слова KEY выполнение данного определения приостановится до тех пор, пока не будет введен некоторый символ. Например, следующее определение выводит на печать по порядку заданное число блоков, начиная с текущего, но, прежде чем приступить к распечатке очередного блока, ожидает нажатия любой клавиши:
: БЛОКИ ( # -- ) SCR @ + SCR @ DO I LIST KEY DROP LOOP ;
В этом случае вы снимаете со стека посредством DROP значение, оставленное словом KEY, так как оно вам не нужно. Позднее мы продемонстрируем использование слова KEY на примере программы ввода
В ряде систем имеется нестандартное слово с именем KEY? (в более ранних системах ?TERMINAL), которое помещает в вершину стека значение истины при нажатии на одну из клавиш, не останавливая вычисления и не ожидая ввода самого символа.
Допустим, вы выполняете бесконечный цикл на прибавление единицы:
: БЕСКОНЕЧНЫЙ 0 BESIN DUP . 1+ FALSE UNTIL DROP ;
Можно организовать выход из такого цикла, заменив слово FALSE на KEY?:
: СКАЖИ-КОГДА 0 BEBIN DUP . 1+ KEY? UNTIL DROP
KEY DROP ;
Слово KEY? не считывает значение символа, соответствующего нажатой клавише, а лишь сигнализирует о том, что одна из клавиш была нажата. Чтобы считать ее значение, вы должны обратиться к слову KEY. В этом месте вы можете либо определить значение нажатой клавиши (при необходимости), либо просто выполнить выражение KEY DROP. (Во многих системах, где есть этап предварительного чтения в буфер, невозможность применять связку KEY KEY?, по существу, сводит на нет описываемый универсальный прием и вынуждает прибегать к системно-зависимым «ухищрениям»).
Если слово KEY ожидает ввода одного символа, то
EXPECT (ОЖИДАТЬ) ожидает ввода с клавиатуры целой строки. На самом деле это адекватно использованию
KEY в цикле. Цикл заканчивается по достижении заданного числа нажатий клавиш (обычно 80) или при нажатии клавиши возврата каретки. Кроме того, слово
EXPECT способно распознать значение клавиши «Забой» и возвратить назад как курсор, так и внутренний указатель слова. С помощью
EXPECT Форт-система ожидает ввода вашей команды.
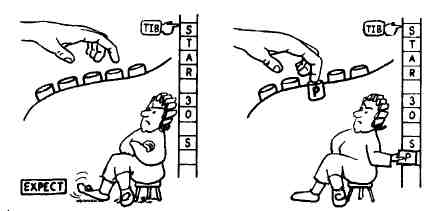
EXPECT выбирает из стека два аргумента: адрес, по которому нужно запомнить вводимый текст, и максимальное значение счетчика. Например, выражение
TIB 80 EXPECT
ожидает ввода до 80 символов или нажатия клавиши RETURN и после завершения набора помещает введенный текст в буфер входного текста. Приведенное выражение содержится в определении слова QUERY (ЗАПРОС), используемое, как было показано выше, словом QUIT.
С помощью EXPECT вы можете сделать запрос на ввод из определения1. Ниже дается слово, которое при своем выполнении запрашивает имя пользователя, а затем выводит введенное имя вместе с приветствием:
CREATE ИМЯ-ПОЛЬЗОВАТЕЛЯ 40 ALLOT
: .ПОЛЬЗОВАТЕЛЬ ИМЯ-ПОЛЬЗОВАТЕЛЯ 40 -TRAILING TYPE ;
: ПОЛУЧЕНИЕ-ИМЕНИ ИМЯ-ПОЛЬЗОВАТЕЛЯ 40 BLANK ИМЯ-ПОЛЬЗОВАТЕЛЯ
40 EXPECT ;
: ВСТРЕЧА CR ." Пожалуйста, введите свое имя: " ПОЛУЧЕНИЕ-ИМЕНИ
CR ." Привет, " .ПОЛЬЗОВАТЕЛЬ ." , Я говорю на Форте." ;
В результате вы получаете2:
ВСТРЕЧА Пожалуйста, введите свое имя: ВАСЯ Привет, ВАСЯ, Я говорю на Форте.
1 для специалистов. Вы можете использовать EXPECT для снятия данных с последовательной шины, например, некоторого измерительного устройства. Так как у вас задействованы адрес и счетчик, такие данные могут быть считаны непосредственно в массив. Если вы являетесь единственным пользованием системы, ю перед записью на диск можете считать данные в буфер. В случае же мультизадачной системы вы должны применить TIB и уже потом пересылать данные в указанный буфер, поскольку «вашим» буфером может воспользоваться другая задача.
2 для пользователей систем, созданных до введения Стандарта-83. Слово EXPECT в таких системах требует наличия нуля в конце вводимого текста. Поэтому при выполнении приведенного выше примера на вашей системе между именем и запятой может появиться пробел. -TRAILING здесь воспринимает нуль как невыводимый на печать символ и при его выводе печатается пробел. Во избежание этого нужно ввести текст посредством EXPECT в рабочую область (PAD), после чего скопировать его, используя SPAN, в слово ИМЯ-ПОЛЬЗОВАТЕЛЯ с требуемым числом символов:
: ПОЛУЧЕНИЕ-ИМЕНИ ИМЯ-ПОЛЬЗОВАТЕЛЯ 40 BLANK PAD 40 EXPECT
PAD ИМЯ-ПОЛЬЗОВАТЕЛЯ SPAN @ CMOVE ;
SPAN - пользовательская переменная, в которой содержится фактическое число символов, полученных словом
EXPECT,
KEY |
( -- с) |
Занесение на стек значения в коде ASCII очередного доступного символа на текущем устройстве ввода. |
EXPECT |
( а u --) |
Ожидание и символов (или нажатий клавиши RETURN) с клавиатуры и запоминание их в участок памяти, начинающийся с адреса a и продолжавшийся сторону увеличения адресов. На нажатие клавиши ЗАБОЙ осуществляется возврат курсора. |
SPAN |
( -- a) |
Содержится количество символов, полученных, словом EXPECT |
Мы рассмотрели выше, каким образом ожидается ввод с клавиатуры. Однако Форт-система позволяет осуществлять ввод и из входного потока. Напоминаем, что входной поток - это последовательность символов, предназначенных для обработки текстовым интерпретатором. Символы могут быть расположены в буфере входного текста (в режиме интерпретации) или в блоке (в режиме загрузки).
Предположим, что пользователь хотел бы иметь возможность задавать свое имя, используя слово Я, например:
Я BACЯ<return>
Пользователь должен набрать фрагмент Я ВАСЯ на одной строке, а затем нажать клавишу RETURN, Нам нужно, чтобы слово Я помещало имя пользователя в массив ИМЯ-ПОЛЬЗОВАТЕЛЯ. Но фрагмент ВАСЯ находится впереди по входному потоку и слово Я, следовательно, не может «ожидать» его с помощью EXPECT, так как он уже введен. Вместо этого необходимо найти средство для чтения опережающего слова.
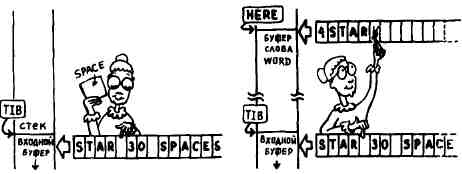
Таким средством является слово WORD (СЛОВО). Оно сканирует входной поток в поисках фрагмента текста, ограниченного символом, код ASCII которого хранится в вершине стека. Например, выражение
BL WORD
будет просматривать входной поток в поисках фрагмента текста, ограниченного пробелами. Найденную подстроку WORD поместит в свой собственный временный буфер вместе со счетчиком символов в первом байте буфера. В Форте строка символов, предваряемая одним байтом, в котором содержится число символов данной строки, называется строкой со счетчиком. Затем WORD вносит в вершину стека адрес своего временного буфера1.
Слово WORD - важный элемент текстового интерпретатора Форта, в котором выражение
BL WORD применяется для сканирования входного потока в поисках слов и чисел.
Пересылая фрагмент текста, WORD дополняет его в конце пробелом, но этот пробел не учитывается в счетчике. Вы можете создать определение Я следующим образом (используя массив, созданный ранее для слова ВСТРЕЧА):
: Я ( имя-пользователя ( -- ) ИМЯ-ПОЛЬЗОВАТЕЛЯ 40 BLANK BL WORD COUNT ИМЯ-ПОЛЬЗОВАТЕЛЯ SWAP CMOVE ;
Чтобы видеть вводимое имя, можно воспользоваться ранее определенным словом .ПОЛЬЗОВАТЕЛЬ.
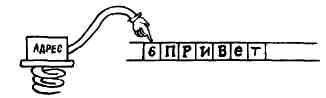
Каковы функции слова COUNT? Это слово разделяет адрес строки со счетчиком на адрес и счетчик. Полученный адрес указывает начало текста, а не байт со счетчиком. Например, при заданном в вершине стека адресе строки со
счетчиком ПРИВЕТ
1 Для пользователей систем фиг-Форта. Ваша версия слова WORD ничего в вершине стека не оставляет. Для обеспечения совместимости с текстом рассматриваемого примера переопределите его:
: WORD ( -- a) WORD HERE ;
слово COUNT заносит в стек счетчик, увеличивает адрес:
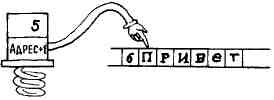
и в вершине стека остаются адрес строки и значение счетчика, которые могут служить аргументами для слов TYPE, CMOVE и т. д.
В нашем определении Я слово WORD оставляет в вершине стека адрес строки со счетчиком, а слово COUNT разделяет этот адрес на адрес и счетчик. Слово АДРЕС-ПОЛЬЗОВАТЕЛЯ обеспечивает адрес назначения. Слово SWAP расставляет аргументы в требуемом порядке (источник - получатель - счетчик) для CMOVE.
Обратите внимание на необычную стековую нотацию слова Я. По существующему соглашению описание, предшествующее стековому комментарию, указывает фрагмент, поиск которого во входном потоке осуществляется в данном определении. Может применяться также символ «\ »:
: Я \ имя-пользователя ( -- ) ИМЯ-ПОЛЬЗОВАТЕЛЯ 40 BLANK BL WORD COUNT ИМЯ-ПОЛЬЗОВАТЕЛЯ SWAP CMOVE ;
Отметим две особенности слова WORD. Первая особенность связана с тем, что, поскольку это слово используется текстовым интерпретатором Форта, найденный им фрагмент будет затерт при чтении следующего фрагмента из входного потока. Введите выражение
BL WORD HI COUNT TYPE
Выражение BL WORD прочитает фрагмент HI и поместит его во временный буфер, но во время интерпретации слова COUNT фрагмент HI будет затерт фрагментом COUNT и в первом байте окажется значение счетчика 5, а не 2. При выполнении слова COUNT в вершину стека заносится значение счетчика 5. Наконец, при интерпретации слова TYPE фрагмент TYPE затрет предыдущий и выведется на экран (включая пробел пятым символом).
Поскольку WORD обычно находится внутри определения, фрагмент, полученный в результате выполнения этого слова, нужно переслать из буфера последнего в более надежное хранилище до считывания из входного потока очередного слова.
Другая особенность слова WORD состоит в том, что оно не воспринимает начальные вхождения символа-ограничителя. Если
в начале некоторого фрагмента набраны пробелы или если слова разделены пробелами, то выражение BL WORD осуществляет поиск до первого значащего символа и считывает фрагмент до первого пробела. Помещаются во временный буфер и учитываются в счетчике только значащие символы. Указанная особенность может вызывать затруднения при работе со словом WORD. Например, в гл. 3 было введено слово .(, обеспечивающее непосредственный вывод на экран очередного фрагмента из входного потока до правой круглой скобки. Это слово может быть определено следующим образом:
: .( \ текст) ( -- ) ASCII ) WORD COUNT TYPE ;
Комментарий означает, что в данном определении фрагмент будет считываться до правой круглой скобки «)». Но в таком определении не предусмотрена ситуация с пустой строкой (без символов):
.() CR CR
Наше определение не воспримет правую круглую скобку, поскольку она является первым просматриваемым символом, а посчитает фрагмент CR CR за строку, которая должна быть выведена на экран. Для подобных ситуаций в ряде Форт-систем имеется слово PARSE (РАЗБОР), функционирующее аналогично слову WORD, но воспринимающее начальные вхождения символа-ограничителя. Помните, что PARSE оставляет в вершине стека адрес строки и значение счетчика, а не адрес строки со счетчиком, как это делает WORD.
Ниже приводится слово, которым вы можете воспользоваться:
: TEXT ( с) PAD 80 BLANK WORD COUNT PAD SWAP CMOVE> ;
Подобно WORD, слово TEXT выбирает из стека символ-ограничитель и сканирует входной поток до тех пор, пока из него не будет считан фрагмент, ограниченный этим символом. Затем фрагмент помещается в рабочую область (PAD). Отличительной чертой TEXT является то, что рабочая область перед занесением строки" заполняется пробелами, что облегчает выполнение слов TYPE и -TRALLING.
WORD |
( с -- а) |
Чтение слова, ограниченного заданным символом, из входного потока. Полученный фрагмент оформляется в виде строки со счетчиком и ее адрес помещается в стек. |
COUNT |
( a -- a+1 #) |
Преобразование адреса строки со счетчиком (длина которой находится в первом строки) в формат, соответствующий использования словом TYPE а именно: в стек заносится адрес начала текста строки и ее длина. |
Вернемся к приведенному выше примеру с генератором бессмысленных сообщений. Хотелось бы иметь при таком генераторе удобные средства введения в базу данных бессмысленных фраз (текстовый редактор Форта не показывает нам, где начинается 20-й или 40-й столбец). Допустим, нам нужно определить для введения в базу данных очередного слова из входного потока слово «добавить»:
начало добавить высокий добавить культурный добавить уровень добавить общий и т.д.
Это можно сделать следующим образом:
\ загрузчик в базу данных бессмысленных сообщений
VARIABLE РЯД
VARIABLE СТОЛБЕЦ
: начало 0 РЯД ! 0 СТОЛБЕЦ ! ;
: +РЯД 1 РЯД +! ;
: +СТОЛБЕЦ СТОЛБЕЦ @ 1+ 3 /МОD РЯД +! СТОЛБЕЦ ! ;
: добавить \ бессмысленная фраза ( -- )
1 WORD COUNT РЯД @ СТОЛБЕЦ @ БРЕД DUP 20 BLANK
SWAP CMOVE UPDATE +СТОЛБЕЦ ;
Обратите внимание на то, как приведенные выше программы вычисляют соответствующие строку и столбец, а также на удачное выделение слова БРЕД, которое оставляет в вершине стека адрес в блоке пересечения заданных строки и столбца.
Кроме того, необходимо отметить, что выражение 1 WORD удачнее выражения BL WORD, поскольку некоторые фразы состоят из двух слов, разделенных пробелами, а мы не хотим считывать только первое слово. Наша цель - считать все, что пользователь ввел до конца строки. В коде ASCII символ 1 является управляющим. Обычно он не может быть введен с клавиатуры и, значит, не может появиться среди символов входного буфера. Поэтому выражение 1 WORD применяется для чтения содержимого входного буфера до того момента, пока пользователь не нажмет клавишу RETURN.
Со словом WORD могут сочетаться и другие ограничители, например кавычки и круглые скобки. Слово Форта ." использует выражение
ASCII " WORD
для чтения из входного потока выводимой строки. Слово ( использует выражение
ASCII ) WORD
для выборки из входного потока фрагмента, который должен быть пропущен. Считывая из входного потока запятые или иные разделители, можно даже обрабатывать несколько фрагментов из одной строки, но из разных полей.
Уже знакомое вам слово TEXT упрощает определение слова «добавить»:
: добавить \ бессмысленную фразу ( -- )
1 TEXT PAD РЯД @ СТОЛБЕЦ @ БРЕД 20 CMOVE UPDATE +СТОЛБЕЦ ;
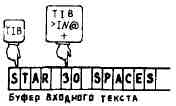
Откуда и что читать, слово WORD «понимает» по двум указателям. Первый из них >IN1 - относительный указатель. Он показывает, на сколько байтов относительно начала буфера входного потока уже продвинулся интерпретатор. Допустим, вы ввели текст
STAR 30 SPACES
и нажали клавишу RETURN. Вначале переменная >IN устанавливается в нуль. После того как слово WORD прочитало строку STAR из входного потока, значение >IN становится равным 5.
1 Для пользователей систем фиг-Форта. В вашей системе это слово IN. Чтобы обеспечить соответствие нашему указателю, переопределите его:
: >IN ( -- a) IN ;
В своих программах вы можете изменять содержимое >IN с тем, чтобы установить необходимый вам порядок интерпретации слов.
Второй указатель - BLK. Вспомните, что входной поток представляет собой последовательность символов, которые могут быть либо в буфере входного текста, либо в загружаемом блоке. Слово BLK указывает, где именно они находятся. Это слово играет роль и флага, и указателя. Если BLK содержит нуль, то WORD сканирует буфер входного текста, а если ненулевое значение, то WORD сканирует блок, номер которого находится в BLK (поэтому вы не можете загружать блок 0).
Ниже показан адрес интерпретируемого в данный момент текста:
СОДЕРЖИМОЕ BLK ТЕКУЩИЙ АДРЕС, ИСПОЛЬЗУЕМЫЙ СЛОВОМ WORD
Нуль TIB >IN " +
(>IN байт относительно начала буфера входного текста)
Не нуль BLK @ BLOCK >IN @ +
(>IN байт относительно начала блочного буфера)
На Форте адрес сканирования для слова WORD вычисляется следующим образом:
... BLK @ ?DUP IF BLOCK ELSE TIB THEN >IN @ + ...
Заметьте, что WORD обращается к слову BLOCK, поэтому если текст интерпретируется из блока, то его содержимое обязательно уже находится в некотором буфере.
>IN |
( -- a) |
Пользовательская переменная, содержания смещение обрабатываемого символа относительно начала входного потока. |
BLK |
( -- а) |
Пользовательская переменная, содержащая номер блока во внешней памяти, интерпретируемого в качестве входного потока. Если в BLK содержится нуль, то входной поток поступает из буфера входного текста. |
Как было показано в гл. 7, с помощью слов <# и #> можно преобразовать число, находящееся в стеке, в строку символов в коде ASCII. Слово CONVERT (ПРЕОБРАЗОВАТЬ) выполняет обратную функцию: оно переводит строку символов ASCII, представляющих некоторое число, в двоичную форму и заносит его в стек.
CONVERT |
( ud1 a1 --
ud2 а2)
|
Начиная с адреса a1+1 (байт, содержащий длину, пропускается), CONVERT преобразует строку в двоичное значение, которое зависит от текущей системы счисления (значения BASE). Полученное значение накапливается в ud1, и остается на стеке как ud2. Процесс продолжается до тех пор, пока не встретится символ, который не может выть истолкован как цифра в текучей системе счисления. Адрес этого символа заносится на стек как а2. |
Приведем несложный пример:
: ПЛЮС \ n2 ( n1 -- сумма ) 0 0 BL WORD CONVERT 2DROP + ;
Это определение можно использовать следующим образом:
12 ПЛЮС 23 . 35 ок
Слово ПЛЮС является лучшим доказательством (для скептиков) того, что в Форте можно применять инфиксную запись выражений. Это слово начинает выполняться при одном занесенном в стек в двоичной форме аргументе 12. В первую очередь, занося в стек нуль двойной длины, мы очищаем место для накопления, после чего слово WORD сканирует входной поток для чтения второго аргумента n2 и оставляет адрес прочитанного фрагмента в вершине стека. Слово CONVERT преобразует строку по заданному адресу (пропуская первый байт со счетчиком) в число двойной длины и заносит его в стек на место нуля. 2DROP удаляет из стека последний адрес, помещенный в него словом CONVERT вместе со старшей ячейкой преобразованного числа, превращая последнее тем самым в число одинарной длины. Наконец, + складывает два верхних числа в стеке.
Если бы слово CONVERT функционировало с такими аргументами:
( а -- ud)
то его можно было бы применять повторно, выполняя преобразования строки, содержащей различные нецифровые символы. Например, строку
6/20/85
можно преобразовать в три числа одинарной длины, трижды подряд обращаясь к CONVERT. Адрес, оставленный в вершине стека при первом применении CONVERT передавался бы аргументом второму CONVERT и т. д.
В большинстве систем имеется слово NUMBER (число), которое выполняет те же функции, но зачастую проще в употреблении. В Стандарте-83 (слова несогласованного набора) это слово определено следующим образом:
NUMBER |
( a -- d) |
Преобразование текста, начинающегося с адреса а+1, в двоичное значение с учетом текущей системы счисления (значения BASE). Строка может предваряться знаком минус, что делает полученное значение отрицательным. |
Поэтому слово ПЛЮС лучше определить так:
: ПЛЮС \ n2 ( n1 -- сумма) BL WORD NUMBER DROP + ;
Слово NUMBER используется и самой ФОРТ-системой. Это «обработчик чисел», к которому обращается текстовый интерпретатор, если искомое слово не найдено в словаре. NUMBER пытается преобразовать полученный фрагмент в число и в случае удачи заносит его значение в стек, при неудаче же осуществляется ABORT.
В каждой Форт-системе процесс преобразования чисел происходит по-своему, так как способов их введения существует очень много. Ниже будет показано одно из возможных определений слова NUMBER, которое воспринимает символы
: , - . /
как правильные пунктуационные знаки, указывающие, что данный фрагмент нужно считать числом двойной длины. Если внутри какого-либо числа появился один из перечисленных символов, то в переменную DPL (положение десятичной точки) заносится количество цифр в числе справа от точки. Например, при вводе фрагмента 200.2 DPL содержит единицу. Если в числе нет знаков пунктуации, то значение DPL окажется равным -1.
\ Определение слова NUMBER
: NUMBER? ( адр - d t-успешное-завершение)
DUP 1+ С@ Получение первой цифры
ASCII - = Это знак минус?
DUP >R Запоминать флага в стеке возвратов
- Если первым символом является "-" , то
к адр добавляется 1, чтобы тот указывал
на первую цифру ( вычитание -1 равносильно
прибавлению 1)
-1 DPL ! Отметка того, что знаков пунктуации
пока нет.
0 0 ROT В качества первоначального накапливаемого
значения берется 0 двойной длины.
BEGIN CONVERT Преобразование до первого символа, не
являющегося цифрой
DUP C@ DUP ASCII : =
SWAP ASCII . ASCII / 1+ Это запятая, дефис, точка или слэш?
WITHIN OR
WHILE 0 DPL ! REPEATE Если да, то переустановить DPL и продолжать
-ROT R> IF DNEGATE THEN Перемещение d в вершину. Если значение
в стеке возвратов указывает минус, то число
делается отрицательным.
ROT С@ BL = ; Является ли последний, непреобраэованный,
символ пробелом, как это и должно быть?
: NUMBER ( адр -- d)
NUMBER? NOT ABORT" ?" ; Если преобразование завершилось неудачей,
то аварийный выход посредством ABORT.
В приведенном определении учитывается, что CONVERT вычитает из DPL по единице при обработке каждой цифры до тех пор, пока значение переменной не станет равным -1. Кроме того, в определении используется слово WITHIN, аналогичное слову ВНУТРИ (см. упражнение к гл. 4).
В качестве «истины» принято арифметическое значение -1, как это определено Стандартом-83. Для более ранних систем, где значением истины является единица, в строке 4 нужно заменить «-» на «+».
В Форте число, вводимое без знаков пунктуации, заносится в стек как число одинарной длины. При рассмотренном здесь определении слова NUMBER текстовый интерпретатор должен обращаться к нему примерно так:
... NUMBER DPL @ -1 = IF DROP THEN ...
В данном разделе мы покажем вам, как слово KEY может быть использовано при разработке специализированного интерпретатора ввода с клавиатуры. Допустим, вы хотите создать слово, подобное EXPECT, которое ожидало бы ввода с клавиатуры, но воспринимало бы только числовые символы. Остальные символы не должны восприниматься. Исключение составляют сигналы, посылаемые при нажатии клавиш ЗАБОЙ (в обычном значении) и RETURN (конец ввода). В отличие от EXPECT ваше слово не будет завершать свое выполнение при вводе заданного числа цифр, так как пользователь может, нажав клавишу ЗАБОЙ, исправить последнюю цифру до нажатия клавиш RETURN. Назовем это слово EXPECT# и зададим ему следующий порядок аргументов:
( a макс-длина -- факт-длина)
где а - поле для размещения строки, а макс-длина - предельное число вводимых цифр. Фактическая длина может понадобиться в том случае, если вы захотите проверить, ввел ли пользователь хотя бы одну цифру.
Вам придется осуществлять такие действия, как возврат курсора на одну позицию, что программируется в разных системах по-разному. Принято вычленять подобные фрагменты в слова Форта и определять их отдельно от остальной части программы. Это делает программу более мобильной, поскольку при смене системы достаточно будет заменить лишь соответствующие слова. Такой прием называется локализацией или упрятыванием информации, не существенной для пользователя. Для большинства компьютеров мы можем написать определение:
: ЗАБОЙ 8 EMIT ;
но в некоторых системах, где применяются устройства вывода с распределенной памятью, могут потребоваться другие определения. Кроме того, символы, получаемые словом KEY при нажатии клавиш ЗАБОЙ и RETURN, в различных системах различны. Упрятывание информации происходит следующим образом:
: ЗБ? ( с -- t=клавиша-забоя) 8 = ; \ в некот.сист. 12 : ВК? ( с -- t=клавиша-RETURN) 13 = ; \ в некот.сист. 0
Основной конструкцией слова EXPECT# является цикл BEGIN WHILE REPEAT. Здесь WHILE выполняет проверку на нажатие клавиши RETURN. Цикл начинается со слова KEY. Если введена правильная цифра, вы обрабатываете ее с помощью слова ПОЛУЧЕНИЕ (посылаете в буфер и увеличиваете соответствующий указатель). В случае «ЗАБОЯ» вы уничтожаете последний символ посредством слова НАЗАД (заполняете пробелом позицию последнего введенного символа и уменьшаете значение указателя). Используя таким образом слово KEY в цикле, можно создавать любые интерпретаторы клавиатуры или редакторы. Последнее определение, ЦИФРЫ, демонстрирует использование слова EXPECT#. Итак, в листинге не осталось больше ничего, что было бы вам не известно, поэтому никаких причин для того, чтобы отложить рассмотрение этой программы, у вас нет. (Более подробную информацию вы найдете в [1].)
Block # 350 0 \ Ввод чисел часть 1 1 2 : НАЗАД 8 EMIT ; 3 : ЗБ? ( с -- t=клавиша-забоя) 8 = ; \ в некот.сист. 12 4 : ВК? ( с -- t=клавиша-RETURN) 13 = ; \ в некот.сист. 0 5 : #? ( с -- t=правильная-цифра) ASCII 0 ASCII 9 1+ WITHIN ; 6 7 8 9 10 11 12 13 14 15
Block # 351 0 \ Ввод чисел часть 2 1 : ПОЛУЧЕНИЕ ( 1-й-адр посл-а+1 текущ-адр с - 1-й-адр 2 посл текущ') 3 >R 2DUP > IF R@ DUP EMIT OVER C! 1+ THEN R> DROP ; 4 : НАОБОРОТ ( 1-й-адр посл-а+1 текущ-адр с -- 1-й-адр поcл 5 текущ' ) 6 DROP SWAP >R 2DUP < IF НАЗАД SPACE НАЗАД 1- DUP 1 BLANK 7 THEN R> SWAP ; 8 : EXPECT# ( а макс-длина -- факт.-длина) 9 OVER + OVER BEGIN KEY DUP ВК? NOT WHILE 10 DUP #? IF ПОЛУЧЕНИЕ ELSE 11 DUP ЗБ? IF НАОБОРОТ ELSE DROP 12 THEN THEN REPEAT ROT 2DROP SWAP - ; 13 14 : ЦИФРЫ ( #цифр -- d) 15 PAD SWAP 2DUP 1+ BLANK EXPECT# DROP PAD 1- NUMBER ;
Для сравнения строк предусмотрены следующие два слова Форта:
-TEXT |
( al # a2 -- ?) |
Сравнение двух строк длиной # , начинающийся с al и а2. Если сравнение успешное, на стек заносится ложь. Если нет, на стек заносится истина (положительное число, если двоичное представление строки1 > двоичного представления строки2, и отрицательное, если стр.1 < стр.2 ). |
-MATCH |
( d # s # -- а ?) |
Поиск фрагмента длиной #, начинающегося с адреса s (источник) в области памяти длиной # , начинающейся с адреса d (получатель). Если поиск завершился успешно, на стек помещается начало искомого фрагмента a заданной области памяти и ложь. В противном случае неправильный адрес и истина. |
С помощью слова -TEXT вы можете либо сравнить две строки, либо проверить порядок их расположения (по алфавиту)1. В гл. 12 приводится пример использования слова -TEXT для выявления полного совпадения строк.
Так как для быстроты слово -TEXT осуществляет сравнение поячеечно, необходимо следить за тем, чтобы при наличии машин с ячеечной адресацией слову -TEXT выдавались адреса, выравненные по границе ячейки. Например, если вы хотите сравнить вводимую строку со строкой, находящейся в каком-то массиве, перенесите вводимую строку в рабочую область (посредством -TEXT, а не WORD), поскольку адрес PAD лежит на границе ячейки. Аналогичным образом, когда вам нужно проверить некую строку, находящуюся в блочном буфере, убедитесь в том, что ее адрес выравнен по границе ячейки, или, если вы не можете этого сделать, перед выполнением проверки перешлите строку по выравненному адресу (используя CMOVE).
Отметим, что дефис в слове -TEXT, как и символ «~» кода ASCII, означает логическое «нет». По этой причине указанный префикс удобно применять в именах слов, помещающих в стек флаги с противоположным логическим значением (т.е. нуль представляет истину, а ненулевое значение - ложь).
Если в вашей системе нет слова -TEXT, вы можете загрузить приведенное ниже определение. Конечно, для быстроты определение слова -TEXT обычно пишется в машинных кодах.
: -TEXT ( a1 # а2 -- f=сравнение | полож=1>2 | отр=1<2 )
2DUP + SWAP DО DROP 2+ DUP 2- @
I @ - DUP IF DUP ABS / LEAVE THEN
2 +LOOP SWAP DROP ;
1 Для пользующихся процессорами INTEL, DEC и Zilog. Для того чтобы выполнить такую проверку, вы должны расположить байты в обратном порядке
Слово -MATCH применяется в командах редактирования, таких, как F и S, по которым должен осуществляться поиск некоторого фрагмента в памяти, содержащей данный фрагмент. Как и в случае с -ТEХТ, желательно, чтобы слово -MATCH было написано в машинных, кодах. Если этого сделать не удается, можете воспользоваться следующим определением высокого уровня, которое вам подойдет (для .надежности и переносимости описанные далее слова не используют такие приемы, как принудительный выход из циклов посредством EXIT, что ускорило бы их выполнение):
VARIABLE 'ИСТОЧНИК ( адрес исходного фрагмента)
VARIABLE ИСТОЧНИК# ( длина исходного фрагмента)
VARIABLE ФЛАГ ( t=сравнвмия-не-прмоошло)
: -MATCH ( d # s # -- a t=cpавнение-не-произошло)
SWAP 'ИСТОЧНИК ! DUP ИСТОЧНИК# ! - DUP 0< NOT IF
1+ 0 DO 0 ФЛАГ !
'ИСТОЧНИК @ ИСТОЧНИК# @ 0 DO
OVER I + С@ OVER I С@ - IF -1 ФЛАГ ! LEAVE THEN
LOOP DROP
ФЛАГ @ 0= IF LEAVE THEN 1+ LOOP
ФЛАГ @ THEN ;
Текстовая строка, скомпилированная в словарь со средствами получения ее адреса, называется строковым литералом. Общим словом для создания строковых литералов является слово STRING (СТРОКА)1. Оно функционирует следующим образом:
CREATE СООБЩЕНИЕ BL STRING ПРИВЕТ СООБЩЕНИЕ COUNT TYPE ПРИВЕТ ok
Слово STRING выбирает из стека в качестве аргумента символ в коде ASCII - ограничитель строки - и считывает до него фрагмент из входного потока, компилируя его в словарь как строку со счетчиком.
1 Для пользователей всех систем, кроме полифорта. Во многих системах (но не всюду) вы можете воспользоваться следующим определением:
: STRING ( с -- ) WORD C@ 1+ ALLOT ;
Мы полагаем, что в таких системах буфер слова WORD начинается с Н ERE, поэтому здесь не требуется пересылка строки и счетчика в словарь. Адрес, оставляемый в стеке словом WORD, является адресом со счетчиком, там что слово С@ помещает значение этого счетчика в вершину стека Затем слово ALLOT продвигает указатель словаря по длине строки (плюс один из-за счетчика), резервируя память для нее в словаре
Вы можете воспользоваться словом STRING для создания строковых массивов. Вспомните наше определение слова МАРКИРОВКА в программе сортировки яиц, где мы применяли вложенные конструкции IF THEN. На этот раз сделаем сообщения о категории яиц одинакового размера (по восемь букв) и соединим их в одну строку с помощью единственного строкового литерала:
CREATE "МАРКИРОВКА" ASCII " STRING Брак Мелкие Средние Крупные Оч.крупнОшибка"
Обращаясь к слову МАРКИРОВКА, мы получаем адрес данной строки. Можно вывести любое сообщение о категории яиц, вычислив смещение внутри строки. Например, если нужно выдать сообщение о категории 2, то добавляем единицу (чтобы проскочить байт со счетчиком), затем прибавляем 16(2*8) и выводим восемь символов имени:
"МАРКИРОВКА" 1+ 16 + 8 TYPE
Теперь переопределим слово МАРКИРОВКА так, чтобы оно выбирало из стека номер категории от нуля до пяти и использовало его как индекс в нашем строковом массиве:
: МАРКИРОВКА ( категория# -- ) 8 * "МАРКИРОВКА" + 8 TYPE SPACE ;
Строковый массив такого вида иногда называют суперстрокой. По соглашению об именовании имя суперстроки должно быть заключено в кавычки.
Новый вариант слова МАРКИРОВКА выполняется немного быстрее, потому что ему не требуется производить ряд операций сравнения до тех пор, пока не будет найдена соответствующая категория. Адрес выводимого сообщения вычисляется по аргументу. Но если аргумент слова МАРКИРОВКА выходит за пределы диапазона от нуля до пяти, то выведется «мусор». В том случае когда слово МАРКИРОВКА используется только внутри слов РАЗМЕР-ЯИЦ, проблем еще нет, однако если вы собираетесь от дать это слово конечному пользователю (т. е. оператору), следует обеспечить контроль:
: МАРКИРОВКА О MAX 5 MIN МАРКИРОВКА ;
Вы встретитесь со словом STRING снова при рассмотрении определения слова ." в гл. 11.
Во многих Форт-системах существует еще одно слово для создания строковых литералов. Это слово не имеет стандартного имени, поэтому присвоим ему имя LIT". Его можно употреблять только внутри определений. Оно подобно слову .", но вместо вывода строки оставляет в вершине стека адрес строки со счетчиком. По существу, выражение
: 1TECT LIT" Что случилось?" COUNT TYPE ;
эквивалентно выражению
: 2TECT ." Что случилось?" ;
Слово LIT" является более мощным, чем STRING (поэтому менее употребительным). Последнее может применяться для определения слова LIT".
В системе-83, созданной Лэксеном и Перри, используется слово ", которое аналогично слову LIT", но оставляет в вершине стека адрес и значение счетчика. По нашему мнению, их вариант разбиения не обеспечивает должной гибкости, поэтому обратимся к варианту LIT". Если вы будете знать, чем отличаются упомянутые варианты, их реализация не вызовет у вас никаких затруднений.
Ниже приводится перечень слов Форта, рассмотренных в настоящей главе.
UPDATE |
( -- ) |
Блок, доступ к которому осуществлялся в последнюю очередь, отмечается как модифицируемый. Этот блок будет впоследствии переписан во внешнюю память, если его буфер потребуется для размещения другого блока или в результате выполнения слова FLUSH. |
SAVE-BUFFERS |
( -- ) |
Запись содержимого всех обновленных буферов в соответствующие блоки внешней памяти. У всех буферов погашается признак обновления, но они продолжают оставаться распределенными . |
FLUSH |
( -- ) |
Осуществляется SAVE-BUFFERS, затем происходит погашение признака обновления всех буферов. Используется при установке или смене накопителей внешней памяти. |
EMPTY-BUFFERS |
( -- ) |
Все блочные буфера отмечаются как пустые независимо от им содержания. Обновленные блоки во внешнюю память не записываются. |
BLOCK |
( u -- ) |
Занесение в стек адреса первого байта в блоке u. Если данного блока еще в памяти нет, то происходит его пересылка из внешней памяти в тот буфер, к которому дольше всех не было доступа. Если блок, занимающий данный буфер, обновлялся (то есть был модифицирован) , то перед считыванием блока u в буфер содержимое последнего будет переписано во внешнюю память. |
BUFFER |
( u -- a) |
Функции те же, что и у BLOCK, за исключением того, что сам блок из внешней памяти не считывается. |
TYPE |
( а количество - ) |
Происходит выдача заданного количества символов, начиная с заданного адреса, на текущее внешнее устройство |
-TRAILING |
( a u1 -- a u2) |
Удаление незначащих пробелов из строки с заданным адресом путем уменьшения значения счетчика от u1 (счетчик исходных байтов) до u2 (счетчик байтов, полученных в результате вычеркивания пробелов). |
>TYPE |
( a # -- ) |
То же самое, что и TYPE, за исключением того, что перед выдачей выводимая строка помещается в pad. Используется в мультипрограммных системах для вывода строк, находящихся в блоках на диске. |
MOVE |
( a1 a2 u -- ) |
По ячеечное копирование участка памяти длиной u байтов, начинающегося с адреса a1, в участок памяти, начинающийся с а2. Пересылка идет с al В сторону увеличения адресов. |
CMOVE |
( al a2 u -- ) |
Побайтное копирование участка памяти длиной u байтов, начинающегося с a1, в участок памяти, начинающийся с а2. Пересылка идет с а1 в сторону увеличения адресов. |
СМОVE> |
( a1 a2 u -- ) |
Копирование участка памяти длиной u байтов, начинающегося с адреса a1, в участок памяти, начинающийся с адреса а2. Копирование начинается с КОНЦА строки и продвигается в сторону уменьшения адресов. |
BLANK |
( a u -- ) |
Заполнение участка памяти длиной u байт символам пробела в коде ASCII. |
KEY |
( -- с) |
Занесение на стек значения в коде ASCII очередного доступного символа на текущем устройстве ввода. |
EXPECT |
( а u --) |
Ожидание и символов (или нажатий клавиши RETURN) с клавиатуры и запоминание их в участок памяти, начинающийся с адреса a и продолжавшийся сторону увеличения адресов. На нажатие клавиши ЗАБОЙ осуществляется возврат курсора. |
SPAN |
( -- a) |
Содержится количество символов, полученных, словом EXPECT |
WORD |
( с -- а) |
Чтение слова, ограниченного заданным символом, из входного потока. Полученный фрагмент оформляется в виде строки со счетчиком и ее адрес помещается в стек. |
COUNT |
( a -- a+1 #) |
Преобразование адреса строки со счетчиком (длина которой находится в первом строки) в формат, соответствующий использования словом TYPE а именно: в стек заносится адрес начала текста строки и ее длина. |
>IN |
( -- a) |
Пользовательская переменная, содержания смещение обрабатываемого символа относительно начала входного потока. |
BLK |
( -- а) |
Пользовательская переменная, содержащая номер блока во внешней памяти, интерпретируемого в качестве входного потока. Если в BLK содержится нуль, то входной поток поступает из буфера входного текста. |
CONVERT |
( ud1 a1 --
ud2 а2)
|
Начиная с адреса a1+1 (байт, содержащий длину, пропускается), CONVERT преобразует строку в двоичное значение, которое зависит от текущей системы счисления (значения BASE). Полученное значение накапливается в ud1, и остается на стеке как ud2. Процесс продолжается до тех пор, пока не встретится символ, который не может выть истолкован как цифра в текучей системе счисления. Адрес этого символа заносится на стек как а2. |
NUMBER |
( a -- d) |
Преобразование текста, начинающегося с адреса а+1, в двоичное значение с учетом текущей системы счисления (значения BASE). Строка может предваряться знаком минус, что делает полученное значение отрицательным. |
-TEXT |
( al # a2 -- ?) |
Сравнение двух строк длиной # , начинающийся с al и а2. Если сравнение успешное, на стек заносится ложь. Если нет, на стек заносится истина (положительное число, если двоичное представление строки1 > двоичного представления строки2, и отрицательное, если стр.1 < стр.2 ). |
-MATCH |
( d # s # -- а ?) |
Поиск фрагмента длиной #, начинающегося с адреса s (источник) в области памяти длиной # , начинающейся с адреса d (получатель). Если поиск завершился успешно, на стек помещается начало искомого фрагмента a заданной области памяти и ложь. В противном случае неправильный адрес и истина. |
| STRING | ( с - ) | Компиляция строкового литерала, ограниченного символом с, в словарь как строки со счетчиком. |
LIT" xxx" |
период-выполнения: ( -- a) |
Компиляция строкового литерала ххх, ограниченного двойной кавычкой. В период выполнения на стек помещается адрес строки со счетчиком. Используется только внутри определений. |
Виртуальная память. Использование внешней памяти (например, диска), так как если бы она была оперативной, включая те средства операционной системы, которые обеспечивают эту возможность.
Ожидание. Приостановка исполнения программы для ожидания ввода с клавиатуры (в противоположность сканированию)
Относительный указатель. Переменная, определяющая абсолютный адрес некоторого участка, а его расположение относительно начала массива или строки.
Сканирование. «Заглядывание» вперед по входному потоку с целью просмотра оставшегося текста или поиска фрагмента, ограниченного заданным символом.
Суперстрока. В Форте - это массив символов, содержащий ряд строк. Доступ к любой из них может быть получен посредством индексирования этого массива.
Упрятывание информации. Прием, используемый программистом: он локализует информацию о том, как работает конкретная конструкция (особенно в тех случаях, когда что-то может измениться в последующих версиях или, будет повторно применяться) в пределах некоторой программы или комплекса программ.
10.1. Введите несколько известных цитат в некоторый доступный блок, скажем в блок 228. Определите слово с именем ЗАМЕНА, которое берет из стека два значения в коде ASCII и заменяет все вхождения первого символа в блоке 228 на второй символ. Так следующее выражение заменит все литеры А литерами Е:
65 69 ЗАМЕНА
10.2. Определите слово с именем ПРОГНОЗ, которое будет выдавать на вашем терминале некоторый прогноз, например «Вы получите хорошие новости по почте>. Прогноз должен выбираться случайным образом из списка, включающего 16 (или менее) вариантов. Каждый прогноз может иметь длину до 64 символов.
10.3. а) Определите слово ДА/НЕТ?, которое можно использовать в прикладной программе, требующей утвердительного или отрицательного ответа пользователя. Определение должно ожидать нажатия одной клавиши, после которого послать в стек значение истина, если была нажата клавиша Y, и ложь при нажатии любой другой клавиши.
б) Иногда пользователь нажимает эту клавишу, работая в режиме нижнего регистра. Перепишите определение ДА/НЕТ? таким образом, чтобы оно воспринимало нажатие клавиши Y в обоих регистрах как «да».
в) Пользователь может по ошибке вместо клавиши Y (например, при записи файла на диск, над которым он проработал последние три часа) нажать другую клавишу. Перепишите определение ДА/НЕТ? таким образом, чтобы оно воспринимало символы, поступающие только при нажатии клавиш Y и N в верхнем и нижнем регистрах и не прекращало своего выполнения до тех пор, пока не получит сигналы от этих клавиш с записью в стек истины в случае Y и лжи в случае N. 10.4. Согласно восточной легенде Будда наделял всех людей, родившихся в определенном году, чертами, присущими одному из 12 животных. На этой основе построен циклический календарь. Цикл составляет 12 лет, по истечении которых он возобновляется. Например, считается, что 1900 год был «годом крысы». Внутри цикла годы, обозначенные названием животного, чередуются в следующем порядке: год крысы, год быка, год тигра, кролика, дракона, змеи, лошади, барана, обезьяны, петуха, собаки, свиньи. Напишите слово с именем ЖИВОТНОЕ, которое бы выводило название конкретного животного в зависимости от его места в приведенном списке, например:
0 .ЖИВОТНОЕ КРЫСА ок
Далее напишите слово с именем (ГОРОСКОП), отражающим искусство составления гороскопа Для рожденных под тем или иным циклическим знаком так, чтобы оно могло брать в качестве аргумента год рождения и выводить название соответствующего животного.
Наконец, напишите слово с именем ГОРОСКОП, которое запрашивало бы у пользователя год рождения. При этом на экран должны выводиться четыре символа подчеркивания, отмечая моле для ввода года рождения, после чет должен отработать четыре раза «ЗАБОЙ», возвращая курсор в первоначальное положение. Используйте определение слова EXPECT#. введенное в настоящей главе («Построение программы ввода чисел с помощью слова KEY».) После нажатия клавиши RETURN на экране должно появиться название соответствующего животного по циклическому календарю.
10.5. В настоящей главе мы определили слово «добавить» для ввода в базу данных бессмысленных фраз. Этот вариант позволяет по каждому такому слону вводить только один фрагмент. Переопределите слово «добавить», чтобы оно выбирало из входного потока по три поля, каждое из которых представляет по одному столбцу и отделяется запятыми, например:
начало добавить высокий, культурный, уровень
При следующем использовании слова «добавить» заполняется очередная строка базы данных.
10.6. Мы полагаем, что слово CONVERT может применяться при анализе числа, представленного, скажем, таким замысловатым способом: «6/20/88». Напишите определение с именем >ДАТА, которое сканировало бы подобные числа но заданному адресу и оставляло в вершине стека дату в виде двух 16-разрядных чисел. При этом старшая ячейка содержала бы год (1988), а младшая - месяц и день, причем месяц бы находился в старшем байте. Затем создайте слово СКАНИРОВАНИЕ-ДАТЫ, которое сканировало бы входной ноток в поисках даты и оставляло бы в вершине стека то же значение, что и слово > ДАТА.
10.7. В гл. 8 было показано, как создаются массивы ячеек (массив из 16-разрядных чисел) в словаре. В данном упражнении нужно создать виртуальный массив (не в оперативной памяти, а на диске), состоящий из 16-разрядных значений. Сначала найдите три доступных смежных блока, где вы будете хранить свой массив. В блоках не должно быть никакой текстовой информации, так как в массиве придется хранить двоичные числа. Определите переменную, которая указывала бы на первый из трех блоков. Далее создайте слово с именем ЭЛЕМЕНТ со следующей стековой нотацией:
( индекс -- адрес)
Это слово переводит индекс ячейки в абсолютный адрес внутри блочного буфера. Обратите внимание на то, что в первом блоке будут храниться только 512 ячеек. Кроме того, оставляемый в вершине стека адрес указывает па второй блок набора и т. д. Слово ЭЛЕМЕНТ также должно вызывать UPDATE.
Теперь созданное вами нужно проверить. Напишите программу инициализации первых 600 ячеек некоторыми значениями и выведите их содержимое па экран, после чего переопределите слово ЭЛЕМЕНТ так, чтобы первый элемент массива резервировался бы для хранения счетчика запомненных элементов Кроме того, определите слово ИСПОЛЬЗОВАНО для занесения в стек значения счетчика. Напишите программу очищения массива. Определите слово ПОМЕСТИТЬ, которое выбирает из стека 16-разрядное значение и добавляет его к массиву на первое свободное место.
Далее определите слово ВВОД, которое добавляет к массиву два 16-разрядных значения, взятых из стека, причем значение, взятое вторым, добавляется первым. И наконец, определите слово ТАБЛИЦА для вывода информации на экран: шестьчисел на строку. (Благодарим за пример К. Хэрриса.)
1. Ham, Michael, "Think Like a User, Write Like a Fox," Forth Dimensions, VI/3, p. 23.